

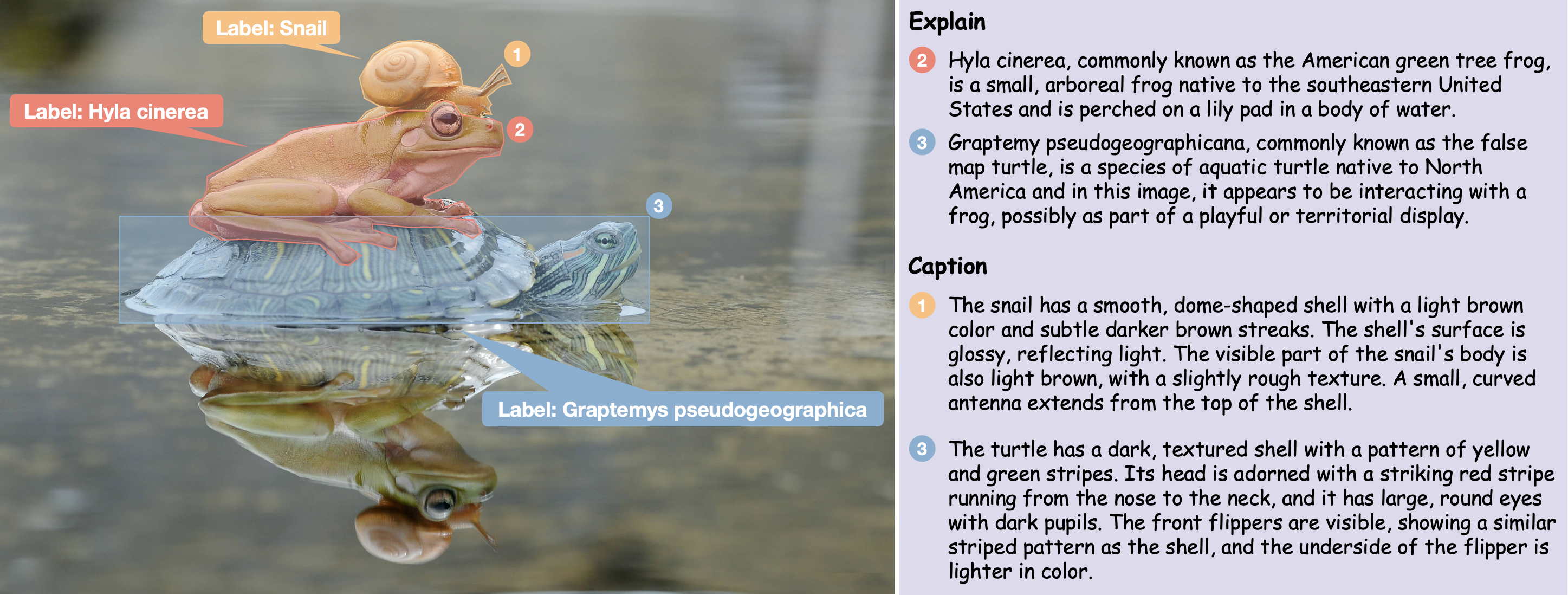
Perceive Anything Model (PAM) is a conceptually simple and efficient framework for comprehensive region-level visual understanding in images and videos. Our approach extends SAM 2 by integrating Large Language Models (LLMs), enabling simultaneous object segmentation with the generation of diverse, region-specific semantic outputs, including categories, label definition, functional explanations, and detailed captions. We propose to efficiently transform SAM 2's rich visual features, which inherently carry general vision, localization, and semantic priors into multi-modal tokens for LLM comprehension. To support robust multi-granularity understanding, we develop a dedicated data refinement and augmentation pipeline, yielding a high-quality dataset of image and video region-semantic annotations, including novel region-level streaming video caption data.
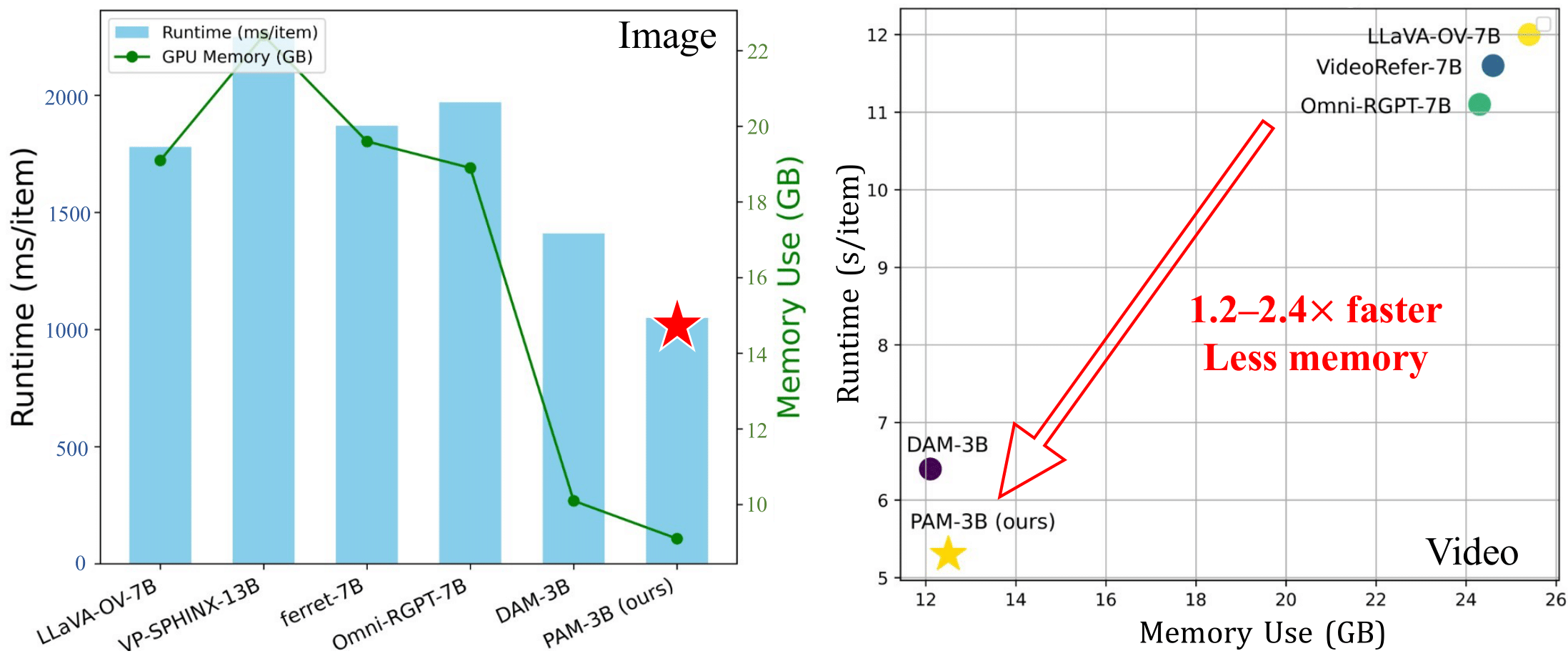
Experimental results demonstrate that PAM delivers robust performance across a diverse range of regional understanding tasks for both images and videos, while operating ⚡️1.2−2.4× faster and consuming less GPU memory compared to prior models. We believe our model, dataset, and insights will significantly advance research in this domain and broadly benefit the vision-language community.
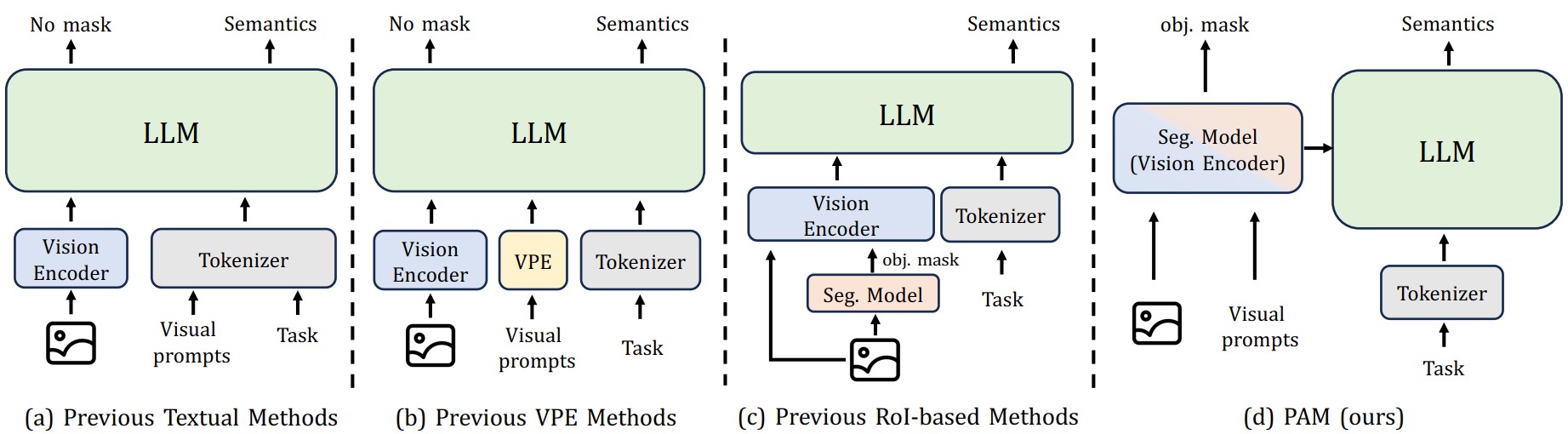
Perceive Anything is also an abbreviation for Pallas Athena. In Homer's epics, Athena and her sacred owl are known for their piercing gaze, capable of perceiving all things in the world. Similarly, our PAM segments every object in any visual medium and simultaneously outputs its semantic meaning.
Given visual prompts such as points, boxes, or masks to specify a region of interest, Perceive Anything Model (PAM) can simultaneously:
(1) Segment: Generate precise segmentation masks for the indicated region within an image or throughout a video.
(2) Recognize: Identify the category of the designated region or object.
(3) Explain: Provide clear explanations of the region's or object's definition, attributes, and functionality within its given context.
(4) Caption: Generate concise or detailed captions for the region within images, videos, and video streams.
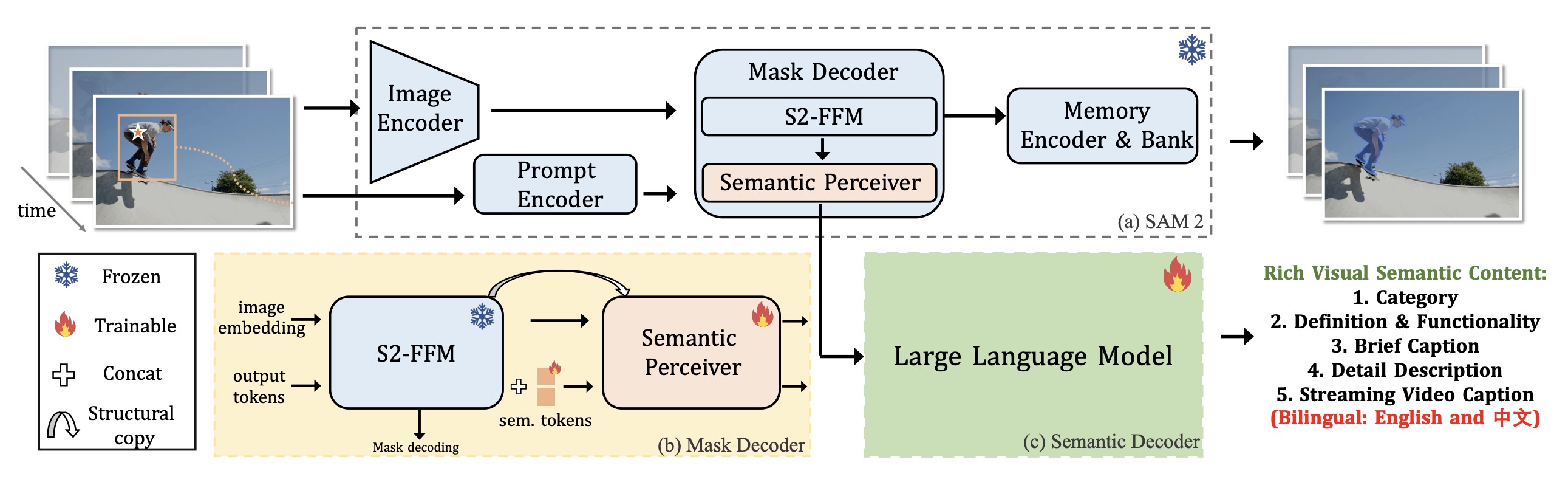
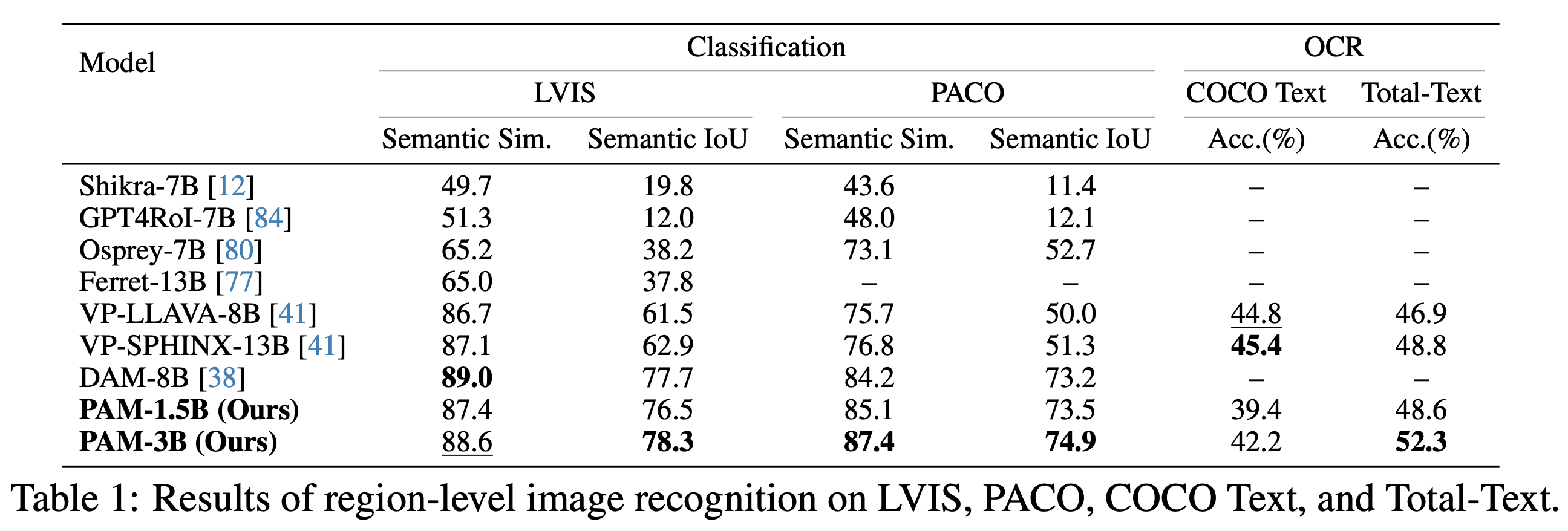
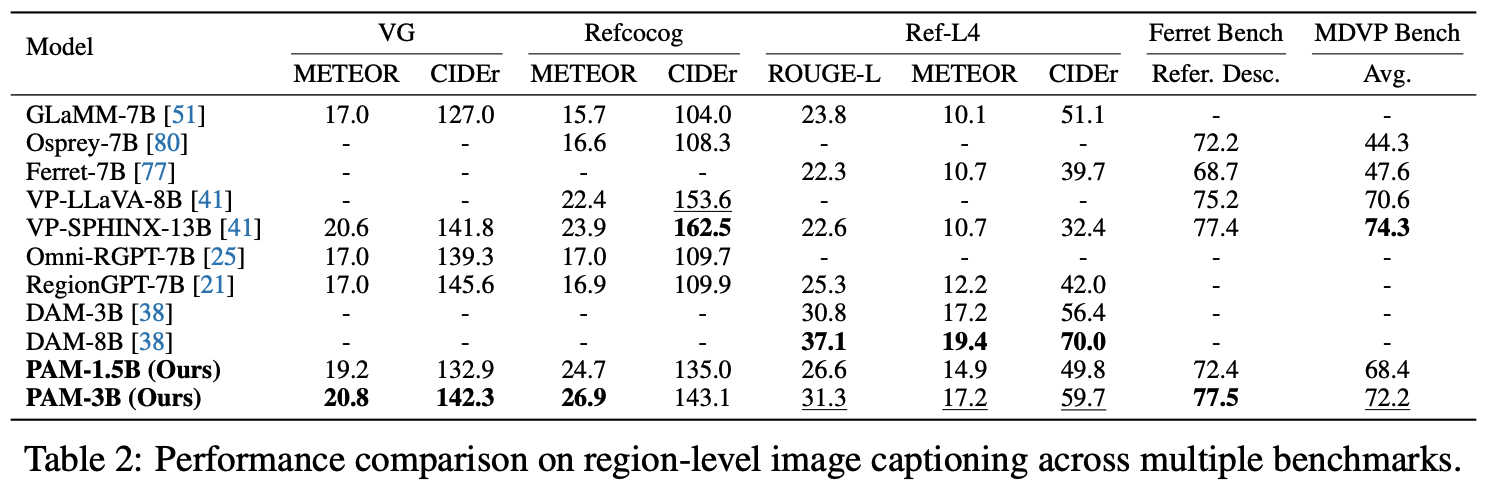
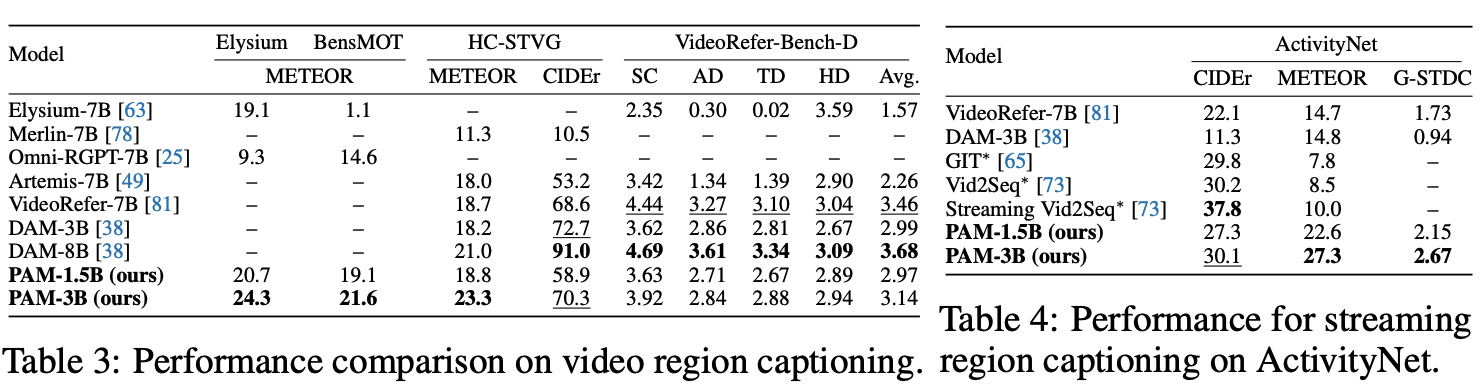
PAM also demonstrates superior inference efficiency and requires less GPU memory for both image and video processing, highlighting its suitability for efficient deployment in real-world applications:
@article{lin2025perceive,
title={Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos},
author={Lin, Weifeng and Wei, Xinyu and An, Ruichuan and Ren, Tianhe and Chen, Tingwei and Zhang, Renrui and Guo, Ziyu and Zhang, Wentao and Zhang, Lei and Li, Hongsheng},
journal={arXiv preprint arXiv:2506.05302},
year={2025}
}



